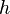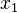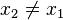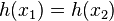ich versuche mal zu erklären, was ich zu dem Thema Kollisionsresistenz bei Hashfunktionen verstanden habe:
Schwache Kollisionsresistenz:
Man hat eine Nachricht mit einen Hashwert vorgegeben. Es ist hier unmöglich eine andere Nachricht zu finden die den gleichen Hashwert hat.
Im Skript wurde das Geburtstagsparadoxon als Beispiel verwendet. Ich würde den zugehörigen Fall darin sehen, wie viele Gäste erscheinen müssen, damit die Wahrscheinlichkeit, dass einer am gleichen Tag Geburtstag hat wie du größer ist als 50%. Wir haben also sozusagen eine vorgegeben Nachricht mit einen Wert (dein Geburtstag) und suchen eine Nachricht mit dem gleichen Wert (also jemanden der am selben Tag Geburtstag hat).
Die Aufgabe 2.6 a) (KE2 S. 84) würde ich auch als schwache Kollisionsresistenz ansehen.
Denn auch hier hat man eine vorgegebene Nachricht und sucht eine andere Nachricht mit dem selben Hashwert.
Starke Kollisionsresistenz:
In diesem Fall hat man sozusagen einen ganzen Topf voll Nachrichten gegeben und sucht sich zwei raus, die den selben Hashwert besitzen. Es gibt also keine vorgegebene Nachricht mehr. Man erzeugt also unterschiedliche Nachrichten bis 2 beliebige von diesen den gleichen Hashwert haben.
Das Beispiel mit dem Geburtstag wäre dann entsprechend: Wie viele Gäste müssen erscheinen, damit die Wahrscheinlichkeit, dass 2 Gäste am gleichen Tag Geburtstag haben größer ist als 50%. Hier haben wir kein festes Datum mehr gegeben. Man hat hier eine Gruppe von Personen und sucht sich die Personen raus, die zufällig am gleichen Tag Geburtstag haben. Der Tag und die Person sind also nicht vorgegeben so wie bei der schwachen Kollisionsresistenz.
Zu der starken Kollisionsresistenz würde ich entsprechend Aufgabe 2.6 b) im Skript zählen. Hier sollen 2 der zufällig erzeugten Nachrichten den gleichen Hashwert haben. Es ist also nicht vorgegeben zu welcher Nachricht mit einem bestimmten Hashwert eine andere Nachricht mit dem selben Hashwert gesucht wird. Beide Nachrichten sind sozusagen beliebig aus den erzeugten Nachrichten wählbar.
Ich hoffe das ist verständlich und nun klarer.
Bitte um Korrektur, wenn ich etwas falsch wiedergegeben bzw. verstanden habe.